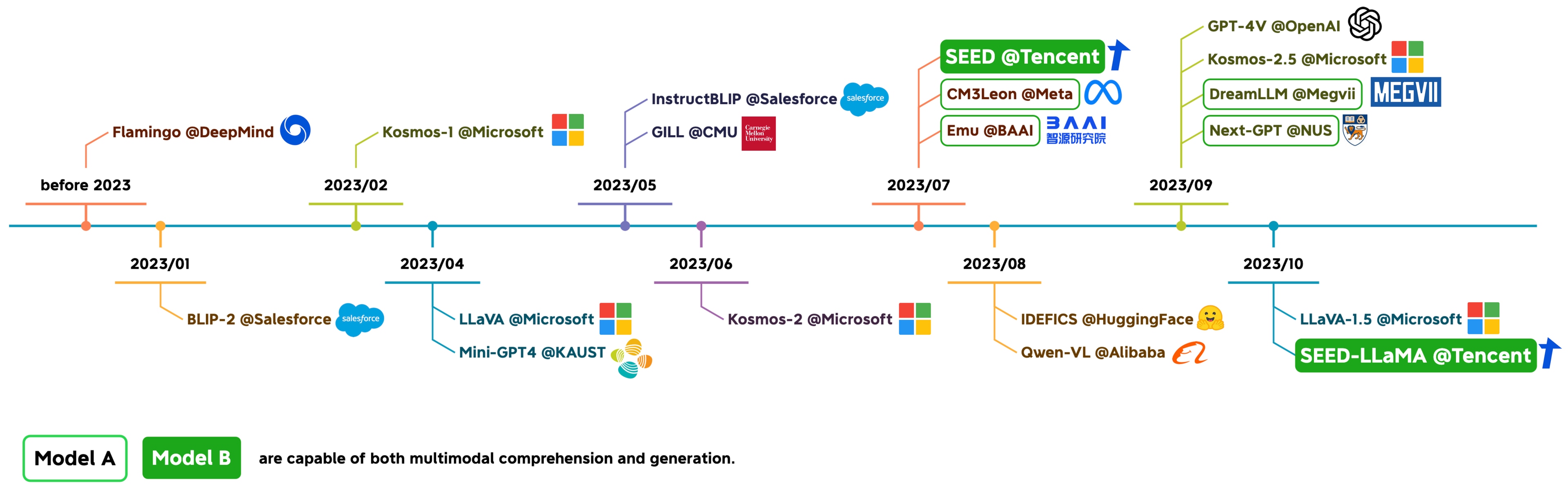
PID Controller for Deep Learning
CVPR 2018 Spotlight paper: A novel approach applying PID control theory to stochastic optimization of deep networks. Extended to IEEE TNNLS with impact factor 11.368. This work bridges control engineering and deep learning optimization.
- CVPR Spotlight
- Optimization
- PyTorch